Stable Diffusion 기술 문서를 읽기 전에 한번 사용해 보는 것도 좋을 듯 합니다. Fine Tuning 기능은 없지만 대략적인 느낌은 알 수 있을듯 합니다. 아래 링크에 사용 방법 설명이 있습니다. 참고 바랍니다.
2023.01.06 - [프로그램 개발해서 돈벌기/AI] - AI 장비 없이 단지 웹에서 AI로 그림 그려보기
AI 장비 없이 단지 웹에서 AI로 그림 그려보기
Stable Diffusion이 2022년도에 출시했습니다. 글을 쓰면 글 내용을 AI가 해석해서 그림을 그려 주는 방식입니다. 보통 실행을 해 보려면 어느 정도 고성능 그래픽 카드를 장착한 PC가 필요합니다. 또는
direction-to-money.tistory.com
Stable Diffusion은 오픈소스로 github에 소스가 공개 되어 있습니다.
https://github.com/CompVis/stable-diffusion
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
A latent text-to-image diffusion model. Contribute to CompVis/stable-diffusion development by creating an account on GitHub.
github.com
Stable Diffusion을 가장 잘 설명한 글이여서 공유해 드립니다. 그리고 나름 이해한 내용을 간략하게 설명 드립니다.
가장 좋은 방법은 아래 원문을 읽어 보는게 가장 좋습니다.
원문 : https://jalammar.github.io/illustrated-stable-diffusion/
The Illustrated Stable Diffusion
Translations: Vietnamese. (V2 Nov 2022: Updated images for more precise description of forward diffusion. A few more images in this version) AI image generation is the most recent AI capability blowing people’s minds (mine included). The ability to creat
jalammar.github.io
The Illustrated Stable Diffusion
그림 1.은 문장이 Stable Diffusion 통해서 이미지를 생성한다는 간략한 설명 그림입니다.

그림 2.는 문장과 이미지가 Stable Diffusion을 통해서 새로운 이미지를 생성하다는 간략한 설명 그림입니다.

Stable Diffusion은 여러 컴포넌트와 모델로 구성된 시스템입니다.
그림 3.은 Stable Diffusion 내부에 Text Understander와 Image Generator가 있는걸 보여줍니다.

그림 4.는 CLIP 모델 텍스트 인코더가 Stable Diffusion 컴포넌트로 있는걸 보여 줍니다.
CLIP에 대한 원문 설명 : https://openai.com/blog/clip/
CLIP: Connecting Text and Images
We’re introducing a neural network called CLIP which efficiently learns visual concepts from natural language supervision.
openai.com

그림 5.는 Image Generator가 Image Information Creator와 Image Decoder로 구성된 것을 보여 줍니다.

그림 6. 처럼 Image Information Creator은 UNet neural network과 scheduling algorithm 구성됩니다.
Image Decoder는 전달 받은 정보로 해당 프로세스가 끝날때 한번 실행해서 그림을 그립니다.

그림 7.은 Stable Diffusion 세 가지 주요 구성 요소입니다.
- ClipText : 텍스트 인코딩
입력: 텍스트.
출력: 각각 768차원의 77개 토큰 임베딩 벡터. - UNet + Scheduler : 정보(잠재) 공간의 정보를 점진적으로 처리/확산
입력: 텍스트 임베딩 및 노이즈로 구성된 시작 다차원 배열( 텐서 라고도 하는 구조화된 숫자 목록).
출력: 처리된 정보 배열 - Autoencoder Decoder : 처리된 정보 배열을 사용하여 최종 이미지를 그림
입력: 처리된 정보 배열(치수: (4,64,64))
출력: 결과 이미지(치수: (3, 512, 512)((빨강/녹색/파랑, 너비, 높이))

그림 8은 Diffusion 작업은 Image Information Creator에서 일어나는 것을 표현했습니다.
- 입력 문장을 대신하는 토큰
- 랜덤 Image Information array
- Image Decoder가 최종 이미지를 그리는 데 사용하는 정보 배열
1, 2번 입력을 받아 3번 정보 배열을 Image Information Creater가 생성 합니다.


Diffusion은 여러 단계로 진행하는 작업입니다. (그림 10.)
각 과정에서 입력하는 배열은 입력 문장과 모든 이미지를 학습한 모델 중 보다 유사한 배열로 생성한 것 입니다.

그림 11.은 각 단계 별로 어떤 정보가 추가 되는지 시각적한 것 입니다.

Diffusion 작동 방식
Diffusion 모델로 이미지를 생성하는 것은 강력한 컴퓨터 비전 모델에 의존합니다.
충분히 큰 데이터셋이 있으면 Diffusion 모델은 복잡한 작업을 학습합니다.
Diffusion 모델은 다음과 같이 framing problem에 의해 이미지 생성을 합니다.
Frame Problem
http://www.aistudy.co.kr/problem/frame_problem.htm
프레임 문제 : Frame Problem
www.aistudy.co.kr
학습힌 샘플 이마자들은 생성한 노이즈와 학습 데이터셋 이미지 추가에 의해 생성됩니다.
- 이미지 선택
- 랜덤 노이즈 생성
- 일정양 노이즈 선택
- 3에서 선택한 양 만큼 노이즈를 이미지에 추가
그림 13-1.은 2단계 노이즈를 선택해서 이미지를 생성한 예입니다.

그림 13-2.는 3단계 노이즈를 선택해서 이미지를 생성한 예입니다.

이 데이터 세트를 사용하여 노이즈 예측기를 훈련하고 특정 설정에서이미지를 생성하는 훌륭한 노이즈 예측기가 됩니다.(그림 14)

UNet 학습 단계 (그림 15)
- 학습 데이터셋에서 학습 샘플 선택
- 노이즈 예측
- 실제 노이즈와 비교(손실 계산)
- 모델 업데이트 (backprop)
backprop
http://aikorea.org/cs231n/optimization-2/
CS231n Convolutional Neural Networks for Visual Recognition
Table of Contents: Introduction Motivation. 이번 섹션에서 우리는 Backpropagation에 대한 직관적인 이해를 바탕으로 전문지식을 더 키우고자 한다. Backpropagation은 네트워크 전체에 대해 반복적인 연쇄 법칙(Cha
aikorea.org

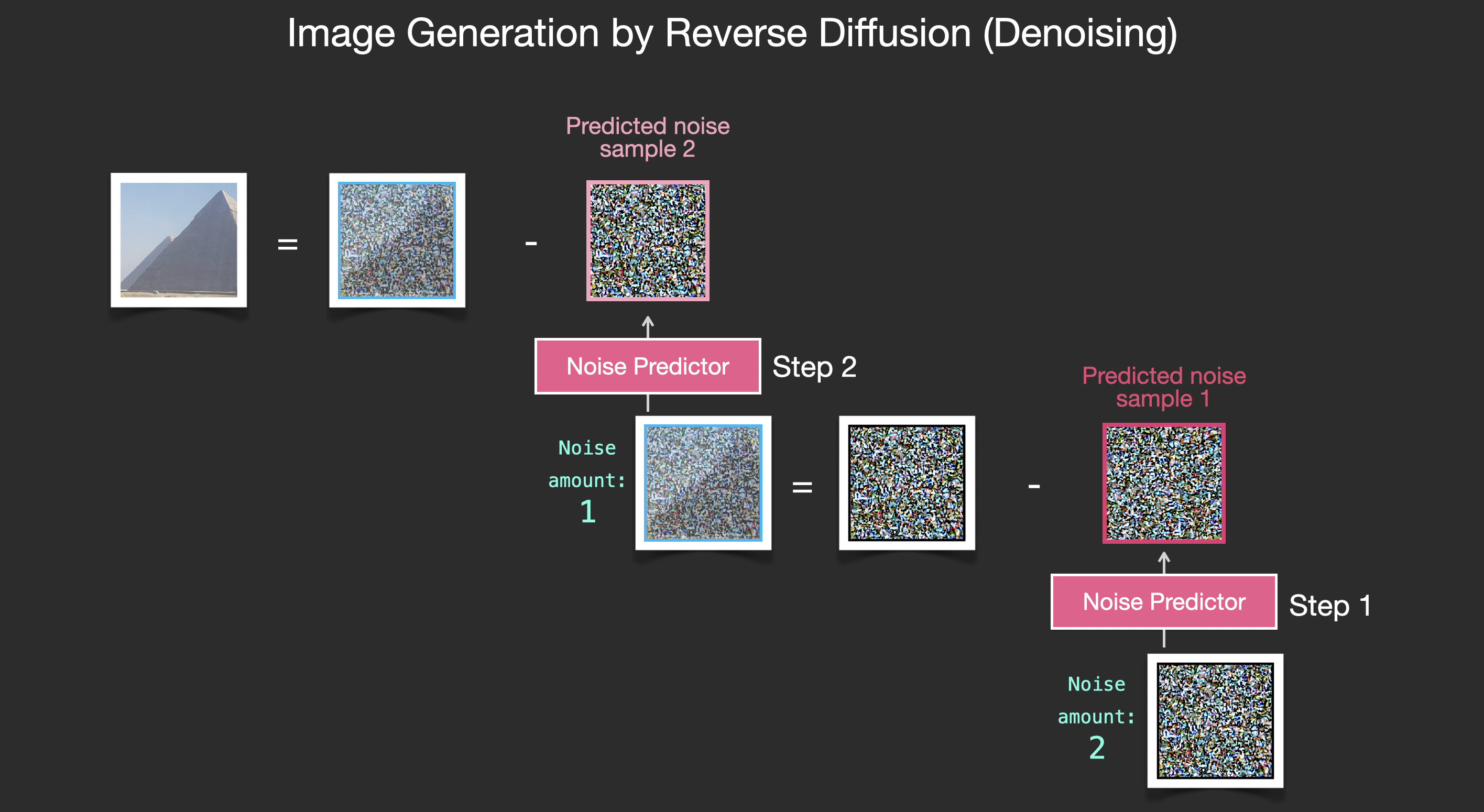
노이즈 제거하며 이미지 생성하기
훈련된 노이즈 예측기는 노이즈 이미지를 가져오고 노이즈 제거 단계 수, 그리고 노이즈 조각을 예측할 수 있습니다. (그림 16.)

만약 이미지에서 빼면 샘플링된 노이즈는 모델이 훈련된 이미지에 더 가까운 이미지를 얻을 수 있게 예측됩니다. (그림 17)
(정확한 이미지가 아닌 분포 - 하늘이 일반적으로 파란색이고 땅 위에 있고, 사람들은 두 개 눈을 가지고 있고, 고양이는 특정한 방식으로 보이는 픽셀 배열의 세계)
속도 향상 : 픽셀 이미지 대신 압축 데이터 Diffusion
이미지 생성 프로세스의 속도를 높이기 위해 Stable Diffusion 페이퍼는 픽셀 이미지 자체가 아닌 이미지의 압축 버전에서 확산 프로세스를 실행합니다. (그림 18.)
LDM/Stable Diffusion 논문 : https://arxiv.org/abs/2112.10752
High-Resolution Image Synthesis with Latent Diffusion Models
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism t
arxiv.org
압축은 자동 인코더를 통해 수행됩니다.
오토인코더는 자신의 인코더를 이용해 영상을 잠재공간으로 압축한 후, 디코더를 이용해 압축된 정보만으로 이미지를 재구성한다.

노이즈 예측기는 실제로 압축된 표현에서 노이즈를 예측하도록 훈련됩니다.
포워드 프로세스(오토인코더의 인코더 사용)는 노이즈 예측기를 훈련하기 위해 데이터를 생성하는 방법입니다.
일단 훈련되면 반대 프로세스를 실행하여 이미지를 생성할 수 있습니다.(오토인코더의 디코더 사용). (그림 19.)

그림 19.동작은 LDM/Stable Diffusion 논문에 있는 그림 20.과 같습니다.

텍스트 인코더: 변환기 언어 모델
Transformer 언어 모델은 텍스트 프롬프트를 받아 토큰 임베딩을 생성하는 언어 이해 구성 요소로 사용됩니다.
Stable Diffusion 모델은 ClipText( GPT 기반 모델 )를 사용하는 반면, 논문은 BERT를 사용 했습니다.
GPT 기반 모델 : https://jalammar.github.io/illustrated-gpt2/
The Illustrated GPT-2 (Visualizing Transformer Language Models)
Discussions: Hacker News (64 points, 3 comments), Reddit r/MachineLearning (219 points, 18 comments) Translations: Simplified Chinese, French, Korean, Russian This year, we saw a dazzling application of machine learning. The OpenAI GPT-2 exhibited impressi
jalammar.github.io
BERT : https://jalammar.github.io/illustrated-bert/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 2021 Update: I created this brief and highly accessibl
jalammar.github.io
Stable Diffusion V2는 OpenClip을 사용합니다. (그림 21.)
https://stability.ai/blog/stable-diffusion-v2-release
Stable Diffusion 2.0 Release — Stability AI
The open source release of Stable Diffusion version 2.
stability.ai

How CLIP is trained
CLIP은 이미지와 해당 캡션의 데이터 세트에 대해 학습됩니다.
4억 개의 이미지와 해당 캡션만 있는 다음과 같은 데이터 세트를 생각해보세요.(그림 22)
CLIP은 웹에서 "alt" 태그로 크롤링된 이미지 학습되었습니다.

CLIP은 이미지 인코더와 텍스트 인코더의 조합입니다.
훈련 과정은 이미지와 캡션을 찍는다고 생각하는 것으로 단순화할 수 있습니다.
이미지와 텍스트 인코더로 각각 인코딩합니다. (그림 23)

cosine similarity를 사용하여 결과 임베딩을 비교합니다.
학습 프로세스를 시작하면 텍스트가 이미지를 올바르게 설명하더라도 유사성이 낮습니다. (그림 24)

다음에 임베딩할 때 결과 임베딩이 유사하도록 두 모델을 업데이트합니다.
데이터 세트 전체에서 큰 배치 크기로 이것을 반복함으로써 인코더가 강아지 이미지와 "a picture of a dog"라는 문장이 유사한 임베딩을 생성할 수 있게 됩니다. word2vec 에서 와 마찬가지로 학습 프로세스에는 일치하지 않는 이미지 및 캡션의 부정적인 예도 포함되어야 하며 모델은 낮은 유사성 점수를 할당해야 합니다. (그림 25)
word2vec : https://jalammar.github.io/illustrated-word2vec/
The Illustrated Word2vec
Discussions: Hacker News (347 points, 37 comments), Reddit r/MachineLearning (151 points, 19 comments) Translations: Chinese (Simplified), French, Korean, Portuguese, Russian “There is in all things a pattern that is part of our universe. It has symmetry
jalammar.github.io

이미지 생성 프로세스에 텍스트 정보 제공
텍스트를 이미지 생성 프로세스의 일부로 만들려면 텍스트를 입력으로 사용하도록 노이즈 예측기를 조정해야 합니다. (그림 26.)

데이터 세트에 인코딩된 텍스트가 포함됩니다.
latent space에서 작동하므로 입력 이미지와 예측된 노이즈가 모두 latent space에 있습니다.(그림 27.)

Unet 노이즈 예측기의 레이어(텍스트 없음)
텍스트를 사용하지 않는 확산유닛을 살펴보자. 입력 및 출력은 다음과 같습니다. (그림 28)

Unet 노이즈 예측기 내부 (그림 29)
- Unet은 잠재 배열을 변환하는 일련의 레이어입니다.
- 각 레이어는 이전 레이어의 출력에 대해 작동합니다.
- 일부 출력은 (잔여 연결을 통해) 나중에 네트워크의 처리에 공급됩니다.
- 타임스텝은 타임스텝 임베딩 벡터로 변환되며 이것이 레이어에서 사용됩니다.

Unet 노이즈 예측기의 레이어(텍스트 있음) (그림 30)

텍스트 입력(기술 용어: 텍스트 컨디셔닝)에 대한 지원을 추가하기 위해 필요한 시스템의 주요 변경 사항은 ResNet 블록 사이에 어텐션 레이어를 추가하는 것입니다. (그림 31)
ResNet 블록은 텍스트를 직접 보지 않습니다.
그러나 attention 레이어는 잠재된 텍스트 표현을 병합합니다.
그리고 이제 다음 ResNet은 통합된 텍스트 정보를 처리에 활용할 수 있습니다.

해당 설명은 구성 컴포넌트 종류와 역할 정도만 설명한 아주 간략한 개념 설명입니다.
링크된 정보와 소스까지 검토해 봐야 개념이 파악될 듯 보입니다.
Good Luck!
'프로그램 개발해서 돈벌기 > AI' 카테고리의 다른 글
| AI 개인 PC(장비) 스펙: PC Hardware for Stable Diffusion (0) | 2023.01.17 |
|---|---|
| DreamBooth : 주어진 사물(인물 포함)을 최대한 보존하면서 새로운 이미지 생성하기 (0) | 2023.01.16 |
| [실습] AI 장비 없이 단지 웹에서 AI로 이미지(그림) 생성(그리기)해 보기 (0) | 2023.01.06 |
| AI가 개발을 같이 해 줘요. (0) | 2022.10.28 |
| [teachable machine] AI 학습 도구 (이미지, 사운드, 자세) (0) | 2022.10.14 |



댓글